
Robot Book Club & the challenges of NLP at Scale

I've been goofing off building a site called Robot Book Club. The eventual goal is to analyze thriller plots, but it's teaching me a lot about the challenges of NLP at scale.
NLP is getting pretty darn good. State of the art, off-the-shelf Named Entity Recognition (NER) can achieve about 90% accuracy at tagging names, places, etc in a document. 90% sounds pretty great.. until you do that math on what that really means for a user.

A novel like Jurassic Park has about 128 thousand words in it. A model that's 90% accurate is going to be making bad calls on THIRTEEN THOUSAND of those words. 90% may be an A- on a test, but it's chasm away from even 5th grade reading comprehension. And the mistakes aren't pretty..

You might think NER errors are all about accidentally missing low incidence names. (That's where humans would stumble.) But it's much worse than that. Look at how something as simple as word order ("Grant and Ellie" versus "Ellie and Grant") changes the output.

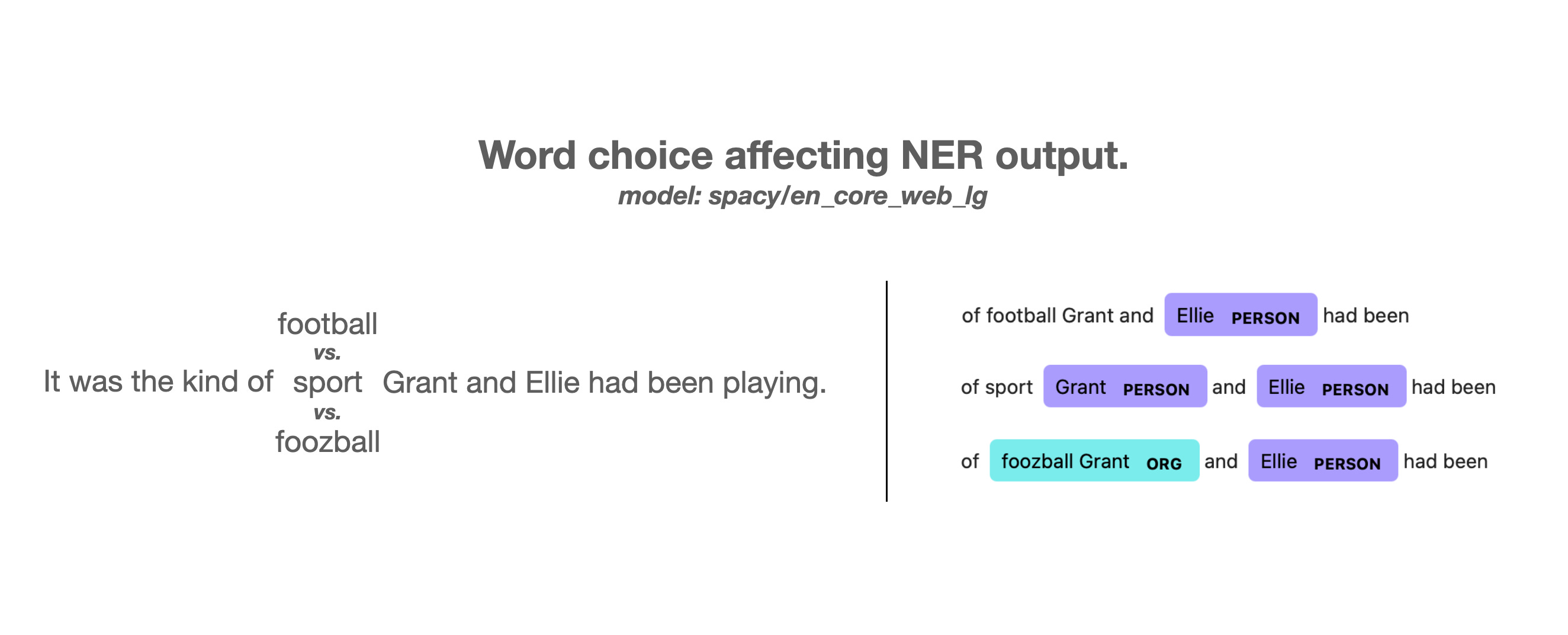
Peripheral word choice influences NER output too. In this sentence, depending on whether the word is "sport", "football", or "foozball", the NER thinks that "Grant" either isn't a person, is a person, or is part of a Foozball organization.
"Just train a better model" isn't the point from a product perspective. Today's model IS yesterday's better model. And that model, at the margins, makes shockingly dumb errors. Or, to be more empathetic to the computer, shockingly non-humanlike errors.
Back to Jurassic Park: here's what these kinds of errors look like when building character timelines for Robot Book Club. We get characters that don't exist, like Grant and Malcom or sboe Ed Regis. And lots of errant false positives on technical jargon and OCR errors.

Looking at these errors reminds me of the "data center math" that companies like Google contend with: at sufficient scale, there's always a hard drive failing somewhere. But unlike a hard drive failure buried in a MapReduce job, NLP errors are visible in the end-product, giving them huge potential to risk user trust. Would you trust a system that gets confused at the difference between "Grant and Ellie" and "Ellie and Grant"?

It's no wonder dialogue systems like Google Assistant still take such rigid, slot-filling approaches in spite of all the recent advances in NLP. These more modern approaches trade precision for recall. And at scale, that small drop in precision is felt enormously. "Better a reliable simpleton than a chaotic savant," is probably an undertone of their strategy.
I don't know what the right answer is, but there are a few obvious strategies to cope with the errors that are inevitably going to arise in the interim between large-scale NLP deployments (already happening) and human-level performance (to come).
Custom Training. The obvious first choice it to train (or fine-tune) models specifically on your dataset rather than use the general purpose models bundled with toolkits. A 2% improvement in accuracy is over 2,000 fewer errors in Jurassic Park. That lessens, though doesn't categorically solve, the problem.
Multi-pass NER. Treat the NER as the first step in a broader system. Collect its results, apply a high-pass filter, and build a gazetteer or fine-tuned model for use with a second pass. This boosts precision at the expense of recall.
Better UX. Design the product acknowledging that the AI is eventually going to make a bad call. Allow humans to suggest corrections. Default to "high confidence" output but offer a "see all output" mode that reveals all output. Create a user mindset of working with the computer.
If you're in the industry and reading this, let me know if I'm missing something or calling it wrong.
Brilliant breakdown of the NLP scale problem; its so true how easily models stumble on the simplest context despite high accuracy. Are you finding that more robust data augmentation helps, or is this still a fundamental architecure challenge?